Architecture
SlateDB is a log-structured merge-tree (LSM-tree). If you are unfamiliar with LSM-trees, we recommend reading the following resources:
This page contains a high-level overview of SlateDB’s architecture, read/write paths, manifest, and compaction. For more details, see SlateDB’s design documents.
Overview
Section titled “Overview”The following diagram shows the architecture of SlateDB:
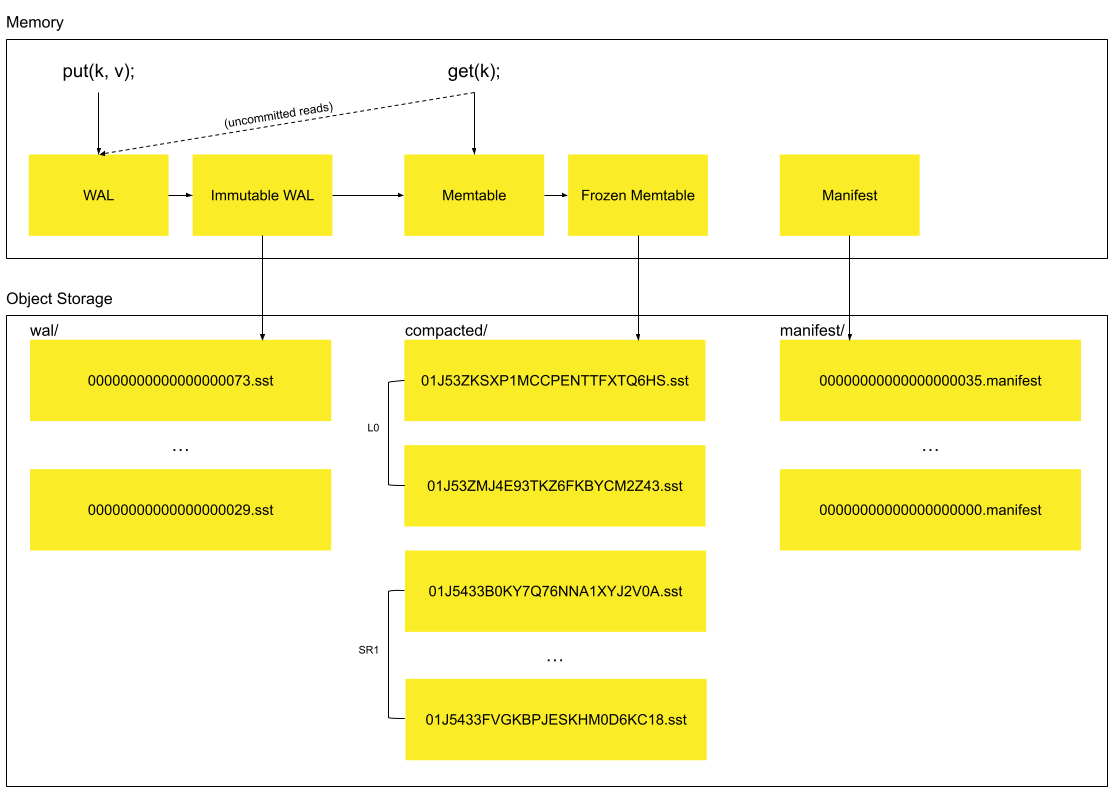
At a high level, SlateDB consists of the following components:
- Write-ahead log (WAL): A mutable WAL that stores recent writes that have not yet been written to object storage.
- Immutable WAL: A WAL that has been frozen and is in the process of being written to object storage in the
waldirectory. - Memtable: An in-memory data structure that stores recent writes that have been written to the object store’s WAL directory, but not yet written to L0.
- Frozen memtable: An immutable memtable that is in the process of being written to object storage in the
compacteddirectory. walSSTs: SSTables that store recent WAL entries on object storage.L0SSTs: SSTables that store recent memtables on object storage.- Sorted runs (SRs): A sequence of compacted, range partitioned SSTables that are treated as a single logical table.
Writes
Section titled “Writes”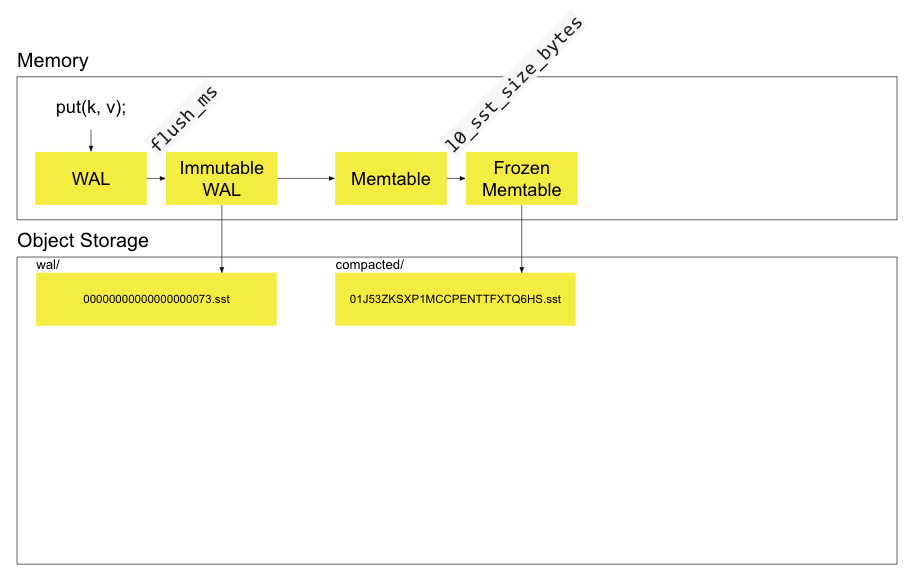
SlateDB’s write path is as follows:
- A
putcall is made on the client. - The key/value pair is written to the mutable, in-memory WAL table.
- After
flush_msmilliseconds, the mutable WAL table is frozen and an asynchronous write to object storage is triggered. - When the write succeeds, insert the immutable WAL into the mutable memtable and notify
await’ing clients. - When the memtable reaches a
l0_sst_size_bytes, it is frozen and written as an L0 SSTable in the object store’scompacteddirectory.
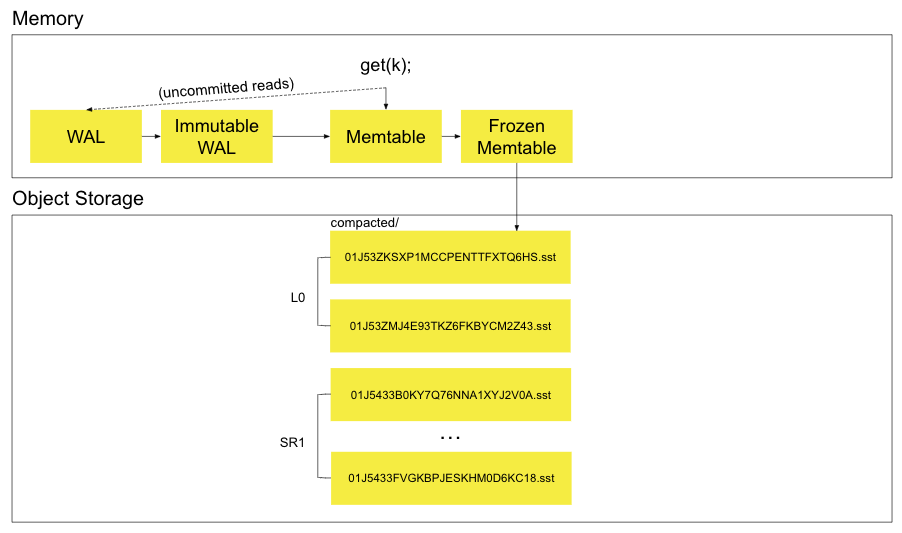
SlateDB’s read path is as follows:
- A
getcall is made on the client. - The value is returned from the mutable memtable if found.
- The value is returned from the immutable memtable(s) if found.
- The value is returned from the L0 SSTables if found (searched from newest to oldest using bloom filtering).
- The value is returned from the sorted runs if found (searched from newest to oldest using bloom filtering).
Manifest
Section titled “Manifest”SlateDB’s manifest file contains the current state of the database, including:
- manifest_id: An auto-incrementing ID that’s incremented every time a new manifest is written.
- writer_epoch: The current writer epoch. This field is used to detect zombie writers. There can be only one active writer at a time. Older writers are fenced off by the newer writer by incrementing this epoch.
- compactor_epoch: The current compactor epoch. As with the
writer_epoch, this field is used to guarantee that there is only one active compactor at a time. - wal_id_last_compacted: The last WAL ID that was contained in a memtable written to L0 at the time the manifest was written. WAL SSTables older than this ID should not be read and are eligible for garbage collection.
- wal_id_last_seen: The most recent WAL ID seen at the head of the WAL at the time the manifest was written.
- l0_last_compacted: The Last L0 SSTable that was compacted at the time the manifest was written. L0 SSTables older than this ID should not be read and are eligible for garbage collection.
- l0: A list of currently available L0 SSTables.
- compacted: A list of sorted runs (SRs) that are currently available to read.
- snapshots: A list of read snapshots. This feature is not yet implemented, but will allow clients to create snapshots. Snapshots will allow writers to have multi-version concurrency control (MVCC) semantics. Readers can use snapshots to ensure they have a consistent view of the state of the database (and that garbage collectors won’t delete SSTables that are still being read).
Compaction
Section titled “Compaction”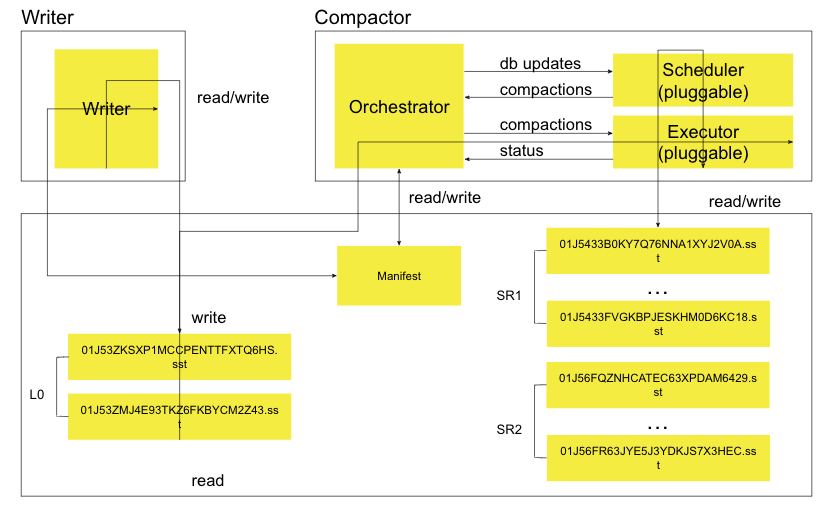
L0 SSTs are written to the compacted directory in the object store when l0_sst_size_bytes is exceeded. SlateDB’s compactor is responsible for merging SSTs from L0 into lower levels (L1, L2, and so on). These lower levels are referred to as sorted runs in SlateDB. Each SST in a sorted run contains a distinct subset of the keyspace.
SlateDB’s compactor has the following components:
- Orchestrator: Runs the compactor’s event loop. Calls out to the scheduler to see if there are any compaction tasks to run. Updates the manifest with the results of compaction.
- Scheduler: Schedules compaction tasks. The scheduler is responsible for determining which SSTs to compact and when to compact them. Though pluggable, the current implementation is a size-tiered compaction strategy.
- Executor: Executes compaction tasks. The executor is responsible for reading SSTs from the object store, merging them, and writing the results back to the object store.
For more details, see SlateDB’s compaction design document.
Backpressure
Section titled “Backpressure”SlateDB uses a backpressure mechanism to prevent writes from overwhelming the compaction process. If the number of SSTs in L0 exceeds a maximum limit (l0_max_ssts), writes to L0 are paused until the compactor can catch up. This cascades upward to the memtable flusher, which will be block writes to its in-memory memtable if max_unflushed_memtable is exceeded.
Garbage Collection
Section titled “Garbage Collection”SlateDB garbage collects old manifests and SSTables. The collector runs in the client process. It will periodically delete:
- Manifests older than
min_agethat are not referenced by any current snapshot. - WAL SSTables older than
min_ageand older thanwal_id_last_compacted. - L0 SSTables older than
min_ageand not referenced by the current manifest or any active snapshot.
Each of these three file types (manifest, WAL SSTable, and L0 SSTable) can be configured with its own min_age and interval parameters. Garbage collection can also be disabled for each file type by setting the corresponding GarbageCollectorOptions attribute to None.